Transformer 的理解
Transformer 是一种基于注意力机制的神经网络架构,它通过并行处理和全局关联让每个元素都能直接"看到"序列中的其他元素,从而高效地捕获长距离依赖关系,彻底改变了自然语言处理、计算机视觉等多个人工智能领域。
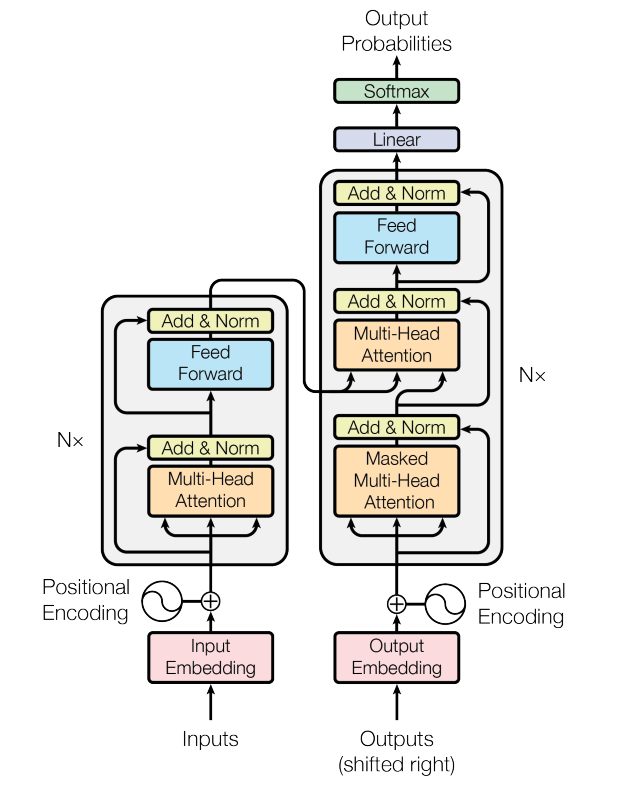
为什么需要 Transformer?
在 Transformer 出现之前,我们处理序列数据(如文本)主要依赖于 RNN(循环神经网络)和 LSTM。但这些模型有一个根本性的限制:它们必须按顺序处理信息。
这种顺序处理有两个主要问题:
- 处理长序列时效率低下(想象一下一个词一个词地读完《战争与和平》)
- 难以捕获远距离的依赖关系(句子开头和结尾的关联容易被"遗忘")
核心洞见:Transformer 的核心创新在于打破了顺序处理的限制,实现了并行计算和全局关联。
Transformer 的核心:注意力机制
如果说 Transformer 是一座桥梁,那么注意力机制就是这座桥的基石。它让模型能够"关注"输入中的不同部分,就像我们阅读时会重点关注某些关键词一样。
注意力机制的工作原理可以简化为三个步骤:
- 查询(Query):当前我们关注的词,比如"深度"
- 计算相关性:衡量"深度"与其他每个词的关联程度
- 加权融合:根据关联程度,将其他词的信息融入到"深度"的表示中
在上图中,当模型处理"深度"这个词时,它会重点关注与之最相关的"学习",形成"深度学习"的语义关联。
核心洞见:自注意力(Self-Attention)是 Transformer 的精髓:每个词都能与序列中的所有词建立直接联系,不受位置远近的限制。
多头注意力:多角度观察
如果说单个注意力机制是从一个角度看问题,那么多头注意力(Multi-head Attention)就是同时从多个角度观察。这就像我们理解一部电影时,会同时关注情节、对白、表演和音乐等多个方面。
多头注意力的好处:
- 增强表达能力:可以捕捉不同类型的语言关系(语法、语义、主题等)
- 提供稳定梯度:改善训练过程,让模型收敛更快更稳定
- 增加鲁棒性:减少了对单一特征的依赖,使模型更加健壮
多头注意力机制让 Transformer 能够同时从多个角度理解输入,类似于人类使用多种感官和认知角度来理解世界。
Transformer 的结构:编码器与解码器
完整的 Transformer 由编码器(Encoder)和解码器(Decoder)组成,但很多现代应用(如 BERT)只使用编码器,而像 GPT 这样的模型则主要基于解码器。
Transformer 的魔力不仅来自于注意力机制,还有一些关键的技术细节:
- 位置编码:由于注意力机制本身不包含位置信息,Transformer 使用特殊的位置编码来告诉模型每个词的位置
- 残差连接:帮助信息在网络中更顺畅地流动,避免梯度消失问题
- 层规范化:稳定训练过程,加速收敛
编码器与解码器的区别
- 编码器:专注于理解输入序列,捕捉上下文信息
- 解码器:专注于生成输出序列,同时关注已生成的内容和编码器提供的上下文
最关键的是两者之间的桥梁:交叉注意力机制,它使解码器能够"查询"编码器获取相关信息,从而生成更准确的输出。
Transformer 的数学原理简述
虽然 Transformer 的核心思想很直观,但它的实现涉及一些数学运算。以自注意力为例:
- 每个输入词被表示为一个向量
- 每个词生成三个向量:查询(Q)、键(K)和值(V)
- 注意力权重的计算公式为:
这个公式看起来复杂,但本质上就是:
- 计算查询与所有键的相似度(QK^T)
- 进行缩放(除以 √d_k)防止梯度消失
- 使用 softmax 将相似度转换为权重
- 用这些权重对值向量进行加权求和
Transformer 的应用:无处不在
自 2017 年提出以来,Transformer 已经成为 AI 领域的基础架构,其应用远超最初的机器翻译任务:
Transformer 派生出的几个重要模型家族:
- BERT(由 Google 开发):专注于理解文本,通过预训练学习双向上下文
- GPT(由 OpenAI 开发):专注于生成文本,每次预测下一个词
- ViT(Vision Transformer):将图像分解为"视觉词元",用 Transformer 处理图像
- Wav2Vec:将语音信号转换为离散表示,再用 Transformer 进行处理
核心洞见:Transformer 之所以能取得如此广泛的成功,是因为它提供了一种通用的方法来处理不同类型的序列数据,无论是文本、图像还是音频。
从原始 Transformer 到现代变体
原始的 Transformer 模型虽然强大,但仍有一些限制。随着研究的深入,Transformer 架构不断演化:
| 模型 | 年份 | 主要改进 |
|---|---|---|
| 原始 Transformer | 2017 | 提出注意力机制和编码器-解码器架构 |
| BERT | 2018 | 双向编码,掩码语言模型预训练 |
| GPT-2 | 2019 | 更大模型,零样本学习能力 |
| T5 | 2020 | 将所有 NLP 任务统一为文本到文本的格式 |
| GPT-3 | 2020 | 极大规模参数,少样本学习能力 |
| ViT | 2020 | 将 Transformer 应用于视觉任务 |
| CLIP | 2021 | 将文本和图像表示在同一空间 |
| DALL-E | 2021 | 从文本描述生成图像 |
| PaLM/GPT-4 | 2022/2023 | 更大规模,多模态,推理能力提升 |
这种演化表明,Transformer 架构具有惊人的适应性和可扩展性,能够应对各种 AI 挑战。
Transformer 的局限性
尽管 Transformer 革命性地改变了 AI 领域,但它也有一些局限性:
- 计算复杂度:标准的自注意力机制的复杂度是 O(n²),其中 n 是序列长度,这使得处理长序列成为挑战
- 位置编码的局限:传统的位置编码无法很好地处理超出训练范围的更长序列
- 训练成本高:预训练大型 Transformer 模型需要大量计算资源
- 解释性差:虽然注意力权重提供了一些可视化,但模型决策过程整体上仍然是个黑盒
为了解决这些问题,研究人员提出了许多改进方案:
- 稀疏注意力机制:如 Reformer、Longformer 等,通过只关注部分位置降低计算复杂度
- 线性注意力:如 Performer、Linear Transformer 等,将复杂度从 O(n²) 降至 O(n)
- 参数共享:如 Albert,通过跨层参数共享减少模型大小
- 知识蒸馏:从大模型中提取知识到小模型,提高效率
Transformer 的本质总结
经过上面的探索,我们可以提炼出 Transformer 架构的三个本质特性:
- 注意力机制:让模型能够选择性地关注输入中的重要部分,类似于人类的注意力焦点
- 并行处理:打破顺序处理的限制,实现高效计算,大幅提升训练和推理速度
- 全局视野:每个位置都能直接"看到"序列中的任何其他位置,解决长距离依赖问题
这三个核心特性共同作用,使 Transformer 成为处理序列数据的强大工具,无论是自然语言、代码、图像、音频还是视频。
展望未来
Transformer 的出现彻底改变了 AI 的发展轨迹。展望未来,我们可以预见几个发展方向:
- 更高效的 Transformer 变体:降低计算复杂度,处理更长序列
- 多模态 Transformer:统一处理文本、图像、音频和视频
- 领域特定的 Transformer:针对科学计算、医疗、金融等特定领域优化
- 更具可解释性的 Transformer:让模型决策过程更加透明
- 结合神经符号方法:将 Transformer 的表示能力与符号推理结合
无论未来如何发展,Transformer 已经成为 AI 历史上的一个里程碑,它不仅是一种模型架构,更是一种思维方式的转变——从顺序到并行,从局部到全局。
总结
Transformer = 注意力机制 + 并行处理 + 全局视野
这个简单而强大的公式,重塑了人工智能的面貌,并将继续影响其未来发展。理解 Transformer 的本质,就是理解现代 AI 的基础。
参考资料
- Vaswani, A., et al. (2017). “Attention is All You Need”. NeurIPS 2017.
- Devlin, J., et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. NAACL 2019.
- Brown, T., et al. (2020). “Language Models are Few-Shot Learners”. NeurIPS 2020.
- Dosovitskiy, A., et al. (2020). “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. ICLR 2021.